FFT는 입력 데이터의 개수
더불어 주기성 때문에
이는 원래의 문제가 처음 입력 데이터의 절반만 가지고 처리하는 두 개의 동일한 문제로 줄일 수 있음을 보여준다. 전형적인 divide and conquer 기법을 적용할 수 있는 구조이므로 매우 빠르게 연산을 수행할 수 있다(Cooley-Tukey algorithm). 역변환의 경우에는 twiddle factor
N=8일 때 전개:
#define TWOPI 6.28318530717958647693
void split(int N, double* data) {
if (N == 8) {
double t1 = data[4]; data[4] = data[1];
double t2 = data[2]; data[2] = t1; data[1] = t2;
t1 = data[5]; data[5] = data[3];
t2 = data[6]; data[6] = t1; data[3] = t2;
return;
}
double *tmp = new double [N / 2];
for (int i = 0; i < N / 2; i++) //copy odd elements to tmp buffer;
tmp[i] = data[2 * i + 1];
for (int i = 0; i < N / 2; i++) // move even elements to lower half;
data[i] = data[2 * i];
for (int i = 0; i < N / 2; i++) // move odd elements to upper half;
data[i + N / 2] = tmp[i];
delete [] tmp;
}
void fft4(double *re, double *im) {
double tr1 = re[0]-re[2]+im[1]-im[3];
double ti1 = im[0]-im[2]-re[1]+re[3];
double tr2 = re[0]+re[2]-re[1]-re[3];
double ti2 = im[0]+im[2]-im[1]-im[3];
double ti3 = im[0]-im[2]+re[1]-re[3];
double tr3 = re[0]-re[2]-im[1]+im[3];
re[0] = re[0]+re[2]+re[1]+re[3];
im[0] = im[0]+im[2]+im[1]+im[3];
re[1] = tr1; im[1] = ti1;
re[2] = tr2; im[2] = ti2;
re[3] = tr3; im[3] = ti3;
}
int fft ( int N, double* re, double* im ) {
if (N <= 0 || N & (N-1)) return 0; // N is not a power of 2;
if ( N < 2 ) return 1;
else if (N == 2) {
double tr1 = re[0]-re[1], ti1 = im[0]-im[1];
re[0] = re[0]+re[1]; im[0] = im[0]+im[1];
re[1] = tr1; im[1] = ti1;
return 1;
} else if (N == 4) {
fft4(re, im);
return 1;
}
split ( N, re);
split ( N, im);
fft ( N / 2, &re[ 0], &im[ 0] );
fft ( N / 2, &re[N / 2], &im[N / 2] );
for ( int k = 0; k < N / 2; k++ ) {
double Ere = re[k];
double Eim = im[k];
double Ore = re[k + N / 2];
double Oim = im[k + N / 2];
double Wre = cos ( TWOPI * k / N ); //real part of twiddle factor:W
double Wim = -sin ( TWOPI * k / N ); //imag part of twiddlw factor:W
double WOre = Wre * Ore - Wim * Oim;
double WOim = Wre * Oim + Wim * Ore;
re[k] = Ere + WOre;
im[k] = Eim + WOim;
re[k + N / 2] = Ere - WOre;
im[k + N / 2] = Eim - WOim;
}
return 1;
};6개의 주파수
int fft_test_main() {
const int samples = 64;
double re[samples], im[samples];
const int nfreqs = 6;
double freq[nfreqs] = {2, 5, 9, 11, 21, 29};
for (int i = 0; i < samples; i++) {
double signal = 0;
for (int k = 0; k < nfreqs; k++)
signal += (k + 1) * cos(TWOPI * freq[k] * i / samples);
re[i] = signal;
im[i] = 0.;
}
fft(samples, &re[0], &im[0]);
for (int i = 0; i < samples; i++) TRACE("%d, %f, %f\n", i, re[i], im[i]);
return 0;
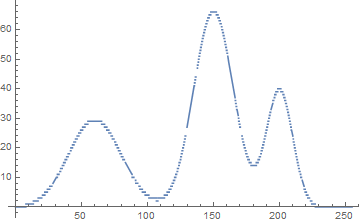
}FFT 결과:

FFT2D
FFT2D
Forward transformation:
kipl.tistory.com
'Image Recognition' 카테고리의 다른 글
| Fixed-Point Bicubic Interpolation (1) | 2021.01.19 |
|---|---|
| Distance Transform (0) | 2021.01.16 |
| Edge-Preserving Smoothing (0) | 2021.01.12 |
| Octree Quantization (0) | 2021.01.12 |
| Median-Cut 컬러 양자화 (0) | 2021.01.12 |