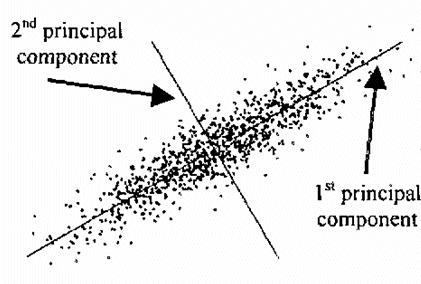
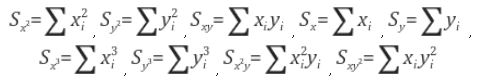이미지 처리 과정에서 미분에 해당하는 그래디언트 필드(gradient field: $g_x$, $g_y$ )를 이용하면 이미지 상의 특징인 corner, edge, ridge 등의 정보를 쉽게 얻을 수 있다. 이미지의 한 지점이 이러한 특징을 가지는 특징점이 되기 위해서는 그래디언트 필드의 값이 그 점 주변에서 (3x3나 5x5정도 크기의 window) 일정한 패턴을 유지해야 한다. 이 패턴을 찾기 위해서 그래디언트 필드에 PCA를 적용해보자. 수평과 수직방향의 그래디언트 field인 $g_x$와 $g_y$ 사이의 covariance 행렬은 다음 식으로 정의된다:
$$ \Sigma = \left [ \begin {array}{cc} < g_x^2 > & < g_x g_y > \\ <g_x g_y> & <g_y^2 > \end {array}\right] =\left [ \begin {array}{cc} s_{xx} & s_{xy} \\ s_{xy} & s_{yy}\end {array}\right];$$
$<...> = \int_{W}(...) dxdy$는 픽셀 윈도에 대한 적분을 의미한다. $\Sigma$의 eigenvalue는 항상 음이 아닌 값을 갖게 되는데 (matrix 자체가 positive semi-definitive), 두 eigenvalue이 $λ_1$, $λ_2$면
$$λ_1 + λ_2 = s_{xx} + s_{yy} \ge 0, \quad \quad λ_1 λ_2 = s_{xx} s_{yy} - s_{xy}^2 \ge0 $$
을 만족한다 (완전히 상수 이미지를 배제하면 0인 경우는 없다). eigenvalue $λ_1$, $λ_2$는 principal axis 방향으로 그래디언트 필드의 변동(분산)의 크기를 의미한다. edge나 ridge의 경우는 그 점 주변에서 잘 정의된 방향성을 가져야 하고, corner의 경우는 방향성이 없어야 한다. edge나 ridge처럼 일방향성의 그래디언트 특성을 갖거나 corner처럼 방향성이 없는 특성을 서로 구별할 수 있는 measure가 필요한데, $λ_1$과 $λ_2$를 이용하면 차원이 없는 measure을 만들 수 있다. 가장 간단한 차원이 없는 측도(dimensionless measure)는 eigenvalue의 기하평균과 산술평균의 비를 비교하는 것이다.
$$ Q = \frac { {λ_{1} λ_{2}} }{ \left( \frac {λ_{1}+λ_{2}}{2} \right)^2} = 4\frac { s_{xx} s_{yy} - s_{xy}^2}{(s_{xx} + s_{yy})^2};$$
기하평균은 산술평균보다도 항상 작으므로
$$ 0 \le Q \le 1 $$
의 범위를 갖는다. 그리고 $Q$의 complement로
$$P = 1-Q = \frac{(s_{xx}-s_{yy})^2 + 4 s_{xy}^2}{(s_{xx}+s_{yy})^2};$$를 정의할 수 있는 데 $0 \le P \le 1$이다. $Q$와 $P$의 의미는 무엇인가? 자세히 증명을 할 수 있지만 간단히 살펴보면 한 지점에서 $Q \rightarrow 1$이려면 $λ_{1} \approx λ_{2}$이어야 하고, 이는 두 주축이 동등하다는 의미이므로 그 점에서는 방향성이 없는 코너의 특성을 갖게 된다. 반대로 $Q \rightarrow 0$이면 강한 방향성을 갖게 되어서 edge(ridge) 특성을 갖게 된다.
실제적인 응용으로는 지문 인식에서 지문 영역을 알아내거나 (이 경우는 상당이 큰 윈도를 사용해야 한다) 또는 이미지 텍스쳐 특성을 파악하기 위해서는 이미지를 작은 블록으로 나누고 그 블록 내의 미분 연산자의 균일성을 파악할 필요가 있는데 이 차원이 없는 측도는 이미지의 상태에 상관없이 좋은 기준을 주게 된다.
참고 논문:
Image field categorization and edge/corner detection from gradient covariance
Ando, S.
Pattern Analysis and Machine Intelligence, IEEE Transactions on
Volume 22, Issue 2, Feb 2000 Page(s):179 - 190
** 네이버 블로그 이전;
'Image Recognition > Fundamental' 카테고리의 다른 글
| Is Power of 2 (0) | 2021.02.12 |
|---|---|
| Flood-Fill and Connected Component Labeling (2) | 2021.02.10 |
| 점증적인 cosine/sine 값 계산 (0) | 2020.12.28 |
| Fast Float Sqrt (0) | 2020.12.27 |
| 2차원 Gaussian 분포 생성 (0) | 2020.12.10 |