Kuwahara filter는 주어진 픽셀을 한 코너로 하는 4개 block 중에서 분산이 가장 작은 블록의 평균으로 중앙 픽셀 값을 대체하는 비선형 filter다. 이 필터를 적용하면 균일한 영역에서 spike noise 픽셀은 주변의 영역의 픽셀 값으로 대체되므로 제거될 수 있고, edge 라인을 기준으로 수직방향으로는 거의 균일한 영역이므로 필터링을 하더라도 edge가 뭉개지지 않음을 알 수 있다. Kuwahara filter는 이미지의 노이즈를 제거하고 edge를(위치) 보존하는 특성을 가진다. 윈도의 크기가 5x5인 경우 4개의 3x3영역에서 평균과 분산을 계산해서 중앙 픽셀의 값을 결정한다. integral 이미지를 사용하면 block의 평균과 분산을 매번 새롭게 계산할 필요가 없으므로 연산 비용이 많이 감소한다.
원본 이미지7x7 필터 적용 결과
Kuwahara filter보다 더 향상된 filter로는 symmetric nearest neighbour (SNN) filter가 있다. 이 filter는 기준 픽셀에서 대칭 지점에 있는 두 지점의 픽셀 값 중에서 중앙 픽셀 값에 가까운 것을 취해서 평균값을 취한다.
아래 코드는 gray 이미지에 대해 Kuwahara filter을 구현한 것으로 컬러 이미지의 경우는 RGB 채널별로 따로 적용하면 된다. 그리고 경계 영역에서는 처리를 하지 않도록 만들었다.
#define GET_SUM(x,y) sum[ (y) * width + (x)]
#define GET_SUM2(x,y) sum2[(y) * width + (x)]
#define BLK_SUM(x,y) ((GET_SUM(x,y) + GET_SUM(x-hs1,y-hs1) \
- GET_SUM(x-hs1,y) - GET_SUM(x,y-hs1)))
#define BLK_SUM2(x,y) ((GET_SUM2(x,y) + GET_SUM2(x-hs1,y-hs1) \
- GET_SUM2(x-hs1,y) - GET_SUM2(x,y-hs1)))
void integral_image(BYTE *image, int width, int height, int *sum);
void integral_image_sq(BYTE *image, int width, int height, int *sum2);
void kuwahara_filter ( BYTE *image, int width, int height, int size, BYTE *out ) {
std::vector<int> sum(width * height, 0);
stt::vector<int> sum2(width * height, 0);
// integral image; for window mean;
integral_image(image, width, height, &sum[0]);
// integral image of square; for window variance;
integral_image_sq(image, width, height, &sum2[0]);
// do filtering;
size = ((size >> 1) << 1) + 1; // make window size be an odd number;
int offset = ( size - 1 ) >> 1;
int hs1 = ( size + 1 ) >> 1;
int nn = hs1 * hs1; // # of pixels within the window;
int var[4], mean[4];
for ( int y = height - hs1; y-- > hs1;) {
for ( int x = width - hs1; x-- > hs1; ) {
mean[0] = BLK_SUM ( x, y ) / nn;
mean[1] = BLK_SUM ( x + offset, y ) / nn;
mean[2] = BLK_SUM ( x, y + offset ) / nn;
mean[3] = BLK_SUM ( x + offset, y + offset ) / nn;
var[0] = BLK_SUM2 ( x, y ) / nn - mean[0] * mean[0];
var[1] = BLK_SUM2 ( x + offset, y ) / nn - mean[1] * mean[1] ;
var[2] = BLK_SUM2 ( x, y + offset ) / nn - mean[2] * mean[2] ;
var[3] = BLK_SUM2 ( x + offset, y + offset ) / nn - mean[3] * mean[3] ;
int vmin = var[0], winner = 0;
for ( int i = 1; i < 4; ++i )
if ( var[i] < vmin )
vmin = var[i], winner = i;
int a = mean[winner];
out[y * width + x] = a > 255 ? 255 : a < 0 ? 0 : a;
}
}
};
이미지 처리에서 각도를 다루게 되면 삼각함수를 이용해야 한다. 일반적인 PC 상에서는 CPU의 성능이 크게 향상이 되어 있고, floating point 연산이 잘 지원이 되므로 큰 문제가 없이 삼각함수를 바로 이용할 수가 있다. 그러나 embeded 환경에서는 연산 속도가 그다지 빠르지 않고 floating point 연산은 에뮬레이션을 하는 경우가 대부분이다. 이런 조건에서 루프 내에서 연속적으로 삼각함수를 호출하는 것은 성능에 많은 영향을 주게 되므로 다른 방법을 고려해야 한다. 일반적으로 각도를 점진적으로 증가시키면 cosine이나 sine 값을 계산해야 할 필요가 있는 경우에는 아래와 같이 처리한다:
for (int i = 0; i < nsteps; ++i) {
double angle = i * angle_increment;
double cos_val = cos( angle ) ;
double sin_val = sin( abgle ) ;
// do something useful with cos_val, and sin_val;
// .......................;
}
물론 미리 계산된 cosine/sine의 값을 가지고 처리할 수도 있다. 하지만 매우 작은 각도 단위로 계산하는 경우는 lookup table의 크기가 매우 커지게 되므로 직접 계산을 하는 것보다 이득이 없을 수 있다. 이런 경우에는 다음의 삼각함수의 관계식을 이용하면 매번 cosine이나 sine 함수의 호출 없이도 필요한 값을 얻을 수 있다;
이미지 처리 연산 과정에서 제곱근 값을 계산해야 경우가 많이 생긴다. 이 경우 math-라이브러리의 sqrt() 함수를 사용하는 것보다 원하는 정밀도까지만 계산을 하는 근사적인 제곱근 함수를 만들어서 사용하는 것이 계산 비용 측면에서 유리할 수 있다.
주어진 양수 $x$의 제곱근 $y = \sqrt{x}$를 구하는 것은 $F(y) = y^2 - x$의 근을 구하는 것과 같다. 프로그램적으로 근은 반복적인 방법에 의해서 구해지는데 많이 사용하는 알고리즘 중 하나가 Newton 방법이다. Newton 방법은 한 단계에서 근의 후보가 정해지면 그 값에서 F에 접하는 직선을 구한 후 그 직선이 가로축과 만나는 점을 다시 새로운 근으로 잡는 반복 과정을 일정한 에러 범위 내에 들어올 때까지 수행한다.
의 형태로 주어진다. 그러나, 이 점화식에는 계산 부하가 상대적으로 큰 나누기 연산이 들어 있다. 그런데 $\sqrt{x} = x \times (1 / \sqrt{x})$로 표현할 수 있으므로 제곱근의 역수를 쉽게 계산하는 알고리즘을 찾으면 된다. $x$의 제곱근의 역수를 구하는 점화식은 (이 경우 $F(y) = 1 / y^2 - x$)
float fast_sqrt(float x) {
xhalf = 0.5F * x;
y = initial_guess_of (1/sqrt(x));
while (error is not small)
// find approx inverse sqrt root of (x);
y = y * 1.5 - y * y * y * xhalf;
end while
// finally return sqrt(x) = x * (1 / sqrt(x));
return (x * y);
}
보통 iteration 횟수는 고정이 되어 있다. 남은 문제는 초기값 추정뿐이다. Newton 방법에서 잘 추정된 초기값은 몇 번의 반복으로도 원하는 정밀도를 얻을 수 있게 하지만 잘못된 추정은 수렴 속도를 더디게 한다. 또한 초기값의 추정 과정도 매우 간단해야 하는데, 좋은 추정을 하기 위해서는 IEEE에서 규정하는 double/float 포맷에 대한 정보와 수치해석 지식이 필요하다.
IEEE의 32비트 float 상수의 비트 구성은 $\tt 0 \sim 22$번째 비트까지는 소수점 아래의 유효숫자(Mantissa: $\tt M$)를 표기하고, $\tt 23$번째부터 $\tt 30$번째까지는 지수 부분(Exponent: $\tt E$)을 표시하는데 $\tt 127$만큼 더해진 값이다(+-지수를 표현하기 위한 것으로 실제 지수는 $\tt e = E - 127$). 마지막 $\tt 31$비트는 부호를 결정한다. 임의의 양의 float 상수 $\tt x$가
$$\tt x = (1 + M) 2^{e} = (1 + M) 2^{E - 127};$$
로 쓰여지면, 정수로 변환된 비트 데이터는 $\tt ix = *(int~*)\&x = (E + M) 2^{23}$의 값을 갖는다. $\tt x$ 제곱근의 역수는
로 표현되므로 비트 데이터에서 지수부는 $\tt (- e / 2) + 127 = 190 - E / 2$로 표현된다.
이제 필요한 것은 잘 선택된 $\tt 1/\sqrt{x}$의 초기값을 찾는 것으로, 첫 번째로 시도할 근사는 유효숫자 부분 $(\tt 1/\sqrt{1 + M})$을 제거하고, 단순히 지수 부분($\tt 2^{- e / 2}$)만 살리면 된다. 정수 표현으로 바꾸면 $\tt 190$이 $\tt 23$에서 $\tt 30$번째 비트를 채우도록 $\tt 23$을 시프트 하고, $\tt - E / 2$ 부분은 원래 float 상수의 정수 표현을 나누면 유효숫자 부분에 해당하는 정도만 에러가 발생한다:
정수 표현 = (190 - E / 2) << 23;
= (190 << 23) - (x의 정수형 변환 & (0xFF << 23)) >> 1;
~ (190 << 23) - (x의 정수형 변환) >> 1; // 유효 숫자 / 2 만큼 에러 발생;
= 0x5F000000 - (*(int *)&x) >> 1;
유효숫자 부분은 좀 더 높은 초기 정밀도를 갖도록 근사를 할 수 있는데 결과만 쓰면 $\tt 0x5F000000$ 대신에 $\tt 0x5F3759DF$를 이용하면 된다.
//빠른 float 제곱근의 역수;
float fast_invsqrt(float x) {
float xhalf = 0.5F * x;
// initial guess of 1 / sqrt(x);
int i = 0x5F3759DF - (*(int *)&x) >> 1;
x = *(float *)&i;
//iterate
x = x * (1.5F - x * x * xhalf);
x = x * (1.5F - x * x * xhalf);
// end of calculation of 1 / sqrt(x);
return (x);
};
// 빠른 float 제곱근;
float fast_sqrt(float x) {
float xhalf = 0.5F * x;
//initial guess of 1 / sqrt(x);
int i = 0x5F3759DF - (*(int *)&x) >> 1;
float y = *(float *)&i;
//iterate
y = y * (1.5F - y * y * xhalf);
y = y * (1.5F - y * y * xhalf);
//end of calculation of 1/sqrt(x);
//return sqrt(x)=x * 1/sqrt(x);
return (x * y)
};
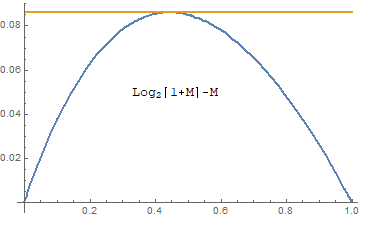
$ \log_2 (x) = e + \log_2 (1 + M)$이므로 x의 근삿값은 $\log_2 (1+M)$의 근삿값을 잘 선택하면 된다. 함수 $f(M)=\log_2 (1+M) - M$는 $M=1/\ln(2)-1$에서 최댓값 $\tt 0.0860713$을 가지므로
그리고 $\delta$는 $x$에 무관한 값이 된다. $x$의 비트 데이터를 정수로 표현하면
$$ i_x= 2^{23} (E+M) = 2^{23}(e + \delta +M) + 2^{23}(127-\delta) \approx 2^{23}\log_2(x) + 2^{23}(127-\delta).$$ 로 근사할 수 있다. 두 번째 항은 $x$에 무관한 값이다. 따라서, 제곱근의 역수에 해당하는 비트 데이터의 근사적인 정수 표현은