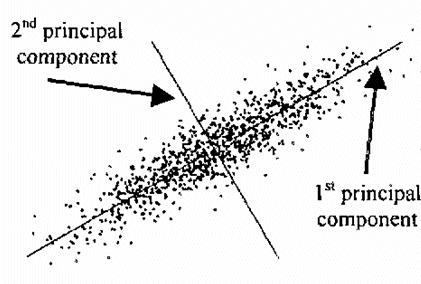
주어진 데이터를 잘 피팅하는 직선을 찾기 위해서는 데이터를 이루는 각 점의 $y$ 값과 같은 위치에서 구하려는 직선과의 차이 (residual)의 제곱을 최소화시키는 조건을 사용한다. 그러나 직선의 기울기가 매우 커지는 경우에는 데이터에 들어있는 outlier에 대해서는 그 차이가 매우 커지는 경우가 발생할 수도 있어 올바른 피팅을 방해할 수 있다. 이를 수정하는 간단한 방법 중 하나는 $y$값의 차이를 이용하지 않고 데이터와 직선 간의 최단거리를 이용하는 것이다.


수평에서 기울어진 각도가 $\theta$이고 원점에서 거리가 $s$인 직선의 방정식은
$$ x \sin \theta - y \cos \theta + s=0$$
이고, 한 점 $(x_i, y_i)$에서 이 직선까지 거리는
$$ d_i = | \sin \theta y_i - \cos \theta x_i + s|$$
이다. 따라서 주어진 데이터에서 떨어진 거리 제곱의 합이 최소인 직선을 구하기 위해서는 다음을 최소화시키는 $\theta, s$을 구해야 한다. $$ L = \sum_i \big( \sin \theta x_i - \cos \theta y_i +s \big)^2 $$$$ (\theta, s)=\text{argmin}(L)$$
$\theta$와 $s$에 대한 극값 조건에서
$$\frac{1}{2} \frac{\partial L}{\partial \theta} = \frac{1}{2} \sin 2 \theta \sum_i (x_i^2 - y_i^2) - \cos 2 \theta \sum x_i y_i + s \sin \theta \sum_i x_i + s \cos \theta \sum_i y_i = 0$$
$$ \frac{1}{2}\frac{\partial L}{\partial s}=\cos \theta \sum y_i - \sin \theta \sum_i x_i - N s=0$$
주어진 데이터의 질량중심계에서 계산을 수행하면 $\sum_i x_i = \sum_i y_i =0$ 이므로 데이터의 2차 모멘트를 $$ A= \sum_i (x_i^2 - y_i^2), \qquad B = \sum_i x_i y_i $$로 놓으면 직선의 파라미터를 결정하는 식은
$$ \frac{1}{2} A \sin 2 \theta - B \cos 2 \theta = 0 \qquad \to \quad \tan 2\theta = \frac{2B}{A} \\ s = 0$$
두 번째 식은 직선이 질량중심(질량중심계에서 원점)을 통과함을 의미한다. 첫번째 식을 풀면
$$ \tan \theta = \frac{- A \pm \sqrt{A^2 + (2B)^2 }}{2B}$$
두 해 중에서 극소값 조건을 만족시키는 해가 직선을 결정한다. 그런데
$$ \frac{1}{2}\frac{\partial^2 L}{\partial \theta^2}= A \cos 2 \theta + 2B \sin 2 \theta = \pm \sqrt{A^2 + (2B)^2} >0$$
이므로 위쪽 부호로 직선($x\sin \theta = y\cos \theta$)이 정해진다. 질량중심계에서는 원점을 지나지만 원좌표계로 돌아오면 데이터의 질량중심을 통과하도록 평행이동시키면 된다.
$$ \left(-A+ \sqrt{A^2+ (2B)^2} \right) (x-\bar{x}) = 2B (y - \bar{y}) $$
여기서 주어진 데이터의 질량중심은 원좌표계에서
$$ \bar{x} = \frac{1}{N} \sum_i x_i, \quad \bar{y} = \frac{1}{N} \sum_i y_i$$
이다. 또한 원좌표계에서 $A$와 $B$의 계산은
$$ A = \sum_i [ (x_i - \bar{x})^2 - (y_i - \bar{y})^2], \qquad B = \sum (x_i - \bar{x})(y_i - \bar{y})$$
이 결과는 데이터 분포에 PCA를 적용해서 얻은 결과와 동일하다. PCA에서는 공분산 행렬의 고유값이 큰 쪽에 해당하는 고유벡터가 직선의 방향을 결정했다. https://kipl.tistory.com/211. 또한 통계에서는 Deming regression이라고 불린다.
PCA Line Fitting
평면 위에 점집합이 주어지고 이들을 잘 기술하는 직선의 방정식을 구해야 할 경우가 많이 발생한다. 이미지의 에지 정보를 이용해 선분을 찾는 경우에 hough transform과 같은 알고리즘을 이용하는
kipl.tistory.com
'Image Recognition > Fundamental' 카테고리의 다른 글
| Approximate Distance Transform (0) | 2024.06.02 |
|---|---|
| Graph-based Segmentation (1) | 2024.05.26 |
| Cubic Spline Kernel (1) | 2024.03.12 |
| Ellipse Fitting (0) | 2024.03.02 |
| Bilateral Filter (0) | 2024.02.18 |