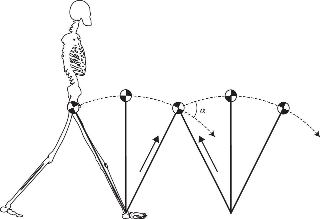
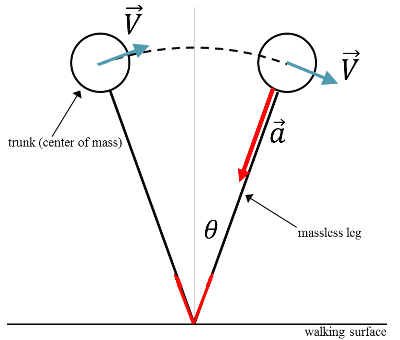
사람이 걷는 동작은 복잡하지만 몇 가지 가정을 하면 단순한 강체의 운동으로 근사를 할 수 있다. 우선 사람이 걷는 동안 항상 한 발은 땅을 딛고 있다. 그리고 땅을 딛고 있는 발을 기준으로 몸의 질량중심은 원호를 그리면서 거의 일정한 속도로 움직이게 된다. 사람을 질량중심에 모든 질량이 뭉친 점으로 근사를 하면 걷는 동작은 거의 질량이 없는 막대(다리: 길이=$L$)에 매달린 역진자(inverted pendulum) 운동과 비슷하다고 볼 수 있다. 또한 원호를 따라 중심이 이동하는 속력은 거의 일정하다고 근사할 수 있다.
이 경우에 질량중심은 등속 원운동을 한다고 볼 수 있고, 뉴턴의 제2법칙에 의해서 질량중심에서 발 쪽을 향하는 힘 성분이 구심력 역할을 한다. 구심력 역학을 할 수 있는 힘은 중력, 수직항력, 그리고 마찰력이 있다.
사람을 너무 단순화시킨 감은 있지만 왜 다리가 긴 사람이 더 빨리 걸을 수 있는지를 물리 법칙으로 추정할 수 있다는 것을 보여준다. 사람을 좀 더 복잡한 강체로 근사하더라도 $\sqrt{gL}$ 앞의 factor만 바뀔 것이다. 사람이 걷는 동안 땅을 딛지 않는 발은 약간 구부러진 상태로 엉덩이를 축으로 일종의 물리진자처럼 행동하는데 이를 이용해도 역시 같은 추정치를 얻을 수 있다.
다리 길이가 $L=1\text{m}$이면, $V_\text{max}= \sqrt{(1 \text{m}) \times (9.8\text{m/s}^2)} = 3.13\text{m/s}=11.3\text{km/h}$. 경보 세계기록이 대략 $15\text{km/h}$이므로 합리적인 추정이 된다.
FFT는 입력 데이터의 개수$(N)$가 2의 지수승으로 주어질 때 $O(N\log N)$의 연산만으로 빠르게 DFT을 수행하는 알고리즘이다. 주어진 $N$개의 data $\{F_0, F_1, ..., F_{N-1}\}$의 DFT $\{a_0, a_1,..., a_{N-1}\}$는
$$ a_k = \sum_{n = 0}^{N-1} F_n \exp\Big( -i \frac{2\pi nk }{N} \Big)=\sum_{n = 0}^{N-1} F_n (W^n )^k , \quad W = \exp\Big( -i \frac{2\pi}{N}\Big)$$ 로 표현된다. $N$이 2의 지수승으로 주어지면 이 합은 $n$이 짝수인 항과 홀수인 항으로 아래처럼 분리할 수 있다:
\begin{align} a_k &= \sum _{n=0}^{N/2-1} F_{2n} (W^{2n})^k+W^{k} \sum_{n=0}^{N/2-1} F_{2n+1}(W^{2n})^k\\ &=\text{(N/2개 even 항에 대한 DFT)} + W^k \times \text{(N/2개 odd 항에 대한 DFT)}\\ &= e_k + W^k o_k \end{align}
이는 원래의 문제가 처음 입력 데이터의 절반만 가지고 처리하는 두 개의 동일한 문제로 줄일 수 있음을 보여준다. 전형적인 divide and conquer 기법을 적용할 수 있는 구조이므로 매우 빠르게 연산을 수행할 수 있다(Cooley-Tukey algorithm). 역변환의 경우에는 twiddle factor $W$를 $W^*$로 바꾸면 되므로(전체 normalization factor $\frac{1}{N}$가 덧붙여진다) 코드에서 쉽게 수정할 수 있다: $\tt W_{im} \rightarrow - { W}_{im}$. 아래는 FFT를 재귀적으로 구현한 코드이다. 비재귀적 구현은 kipl.tistory.com/22에서 찾을 수 있다.
$F_n$ 인덱스의 이진비트가 twiddlefactor를 어떻게 곱해야 하는지 알려주고, 비트를 역으로 읽으면 계수가 나타나는 순서를 알 수 있게 한다.
#define TWOPI 6.28318530717958647693
void split(int N, double* data) {
if (N == 8) {
double t1 = data[4]; data[4] = data[1];
double t2 = data[2]; data[2] = t1; data[1] = t2;
t1 = data[5]; data[5] = data[3];
t2 = data[6]; data[6] = t1; data[3] = t2;
return;
}
double *tmp = new double [N / 2];
for (int i = 0; i < N / 2; i++) //copy odd elements to tmp buffer;
tmp[i] = data[2 * i + 1];
for (int i = 0; i < N / 2; i++) // move even elements to lower half;
data[i] = data[2 * i];
for (int i = 0; i < N / 2; i++) // move odd elements to upper half;
data[i + N / 2] = tmp[i];
delete [] tmp;
}
void fft4(double *re, double *im) {
double tr1 = re[0]-re[2]+im[1]-im[3];
double ti1 = im[0]-im[2]-re[1]+re[3];
double tr2 = re[0]+re[2]-re[1]-re[3];
double ti2 = im[0]+im[2]-im[1]-im[3];
double ti3 = im[0]-im[2]+re[1]-re[3];
double tr3 = re[0]-re[2]-im[1]+im[3];
re[0] = re[0]+re[2]+re[1]+re[3];
im[0] = im[0]+im[2]+im[1]+im[3];
re[1] = tr1; im[1] = ti1;
re[2] = tr2; im[2] = ti2;
re[3] = tr3; im[3] = ti3;
}
int fft ( int N, double* re, double* im ) {
if (N <= 0 || N & (N-1)) return 0; // N is not a power of 2;
if ( N < 2 ) return 1;
else if (N == 2) {
double tr1 = re[0]-re[1], ti1 = im[0]-im[1];
re[0] = re[0]+re[1]; im[0] = im[0]+im[1];
re[1] = tr1; im[1] = ti1;
return 1;
} else if (N == 4) {
fft4(re, im);
return 1;
}
split ( N, re);
split ( N, im);
fft ( N / 2, &re[ 0], &im[ 0] );
fft ( N / 2, &re[N / 2], &im[N / 2] );
for ( int k = 0; k < N / 2; k++ ) {
double Ere = re[k];
double Eim = im[k];
double Ore = re[k + N / 2];
double Oim = im[k + N / 2];
double Wre = cos ( TWOPI * k / N ); //real part of twiddle factor:W
double Wim = -sin ( TWOPI * k / N ); //imag part of twiddlw factor:W
double WOre = Wre * Ore - Wim * Oim;
double WOim = Wre * Oim + Wim * Ore;
re[k] = Ere + WOre;
im[k] = Eim + WOim;
re[k + N / 2] = Ere - WOre;
im[k + N / 2] = Eim - WOim;
}
return 1;
};
6개의 주파수 $\{f_i = 2, 5, 9, 11, 21, 29\text{Hz}\}$가 섞인 신호 $s(t)$를 $[0,1]$ 초 구간에서 일정한 간격으로 sampling 해서 64개 data를 얻고(Nyquist frequency = 32Hz), 이에 대해 FFT를 수행한다.
$$s(t)=\sum_{i=0}^{5} (i+1) \cos(2\pi f_i t) $$
int fft_test_main() {
const int samples = 64;
double re[samples], im[samples];
const int nfreqs = 6;
double freq[nfreqs] = {2, 5, 9, 11, 21, 29};
for (int i = 0; i < samples; i++) {
double signal = 0;
for (int k = 0; k < nfreqs; k++)
signal += (k + 1) * cos(TWOPI * freq[k] * i / samples);
re[i] = signal;
im[i] = 0.;
}
fft(samples, &re[0], &im[0]);
for (int i = 0; i < samples; i++) TRACE("%d, %f, %f\n", i, re[i], im[i]);
return 0;
}
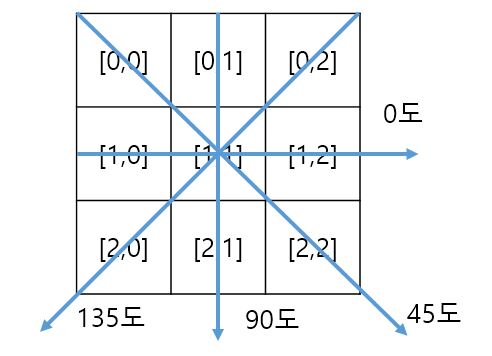
Edge를 보존하는 low-pass filter로 주어진 픽셀 값을 그 위치에서 edge 방향을 따라 구한 평균값으로 대체한다. 방향은 8방향 (45도) 기준이다. Edge의 방향은 그림처럼 중심 픽셀을 기준으로 주변의 8개를 픽셀을 이용해서 45도씩 회전하면서 차이(평균 변화율)를 계산하여 가장 작은 값을 주는 방향으로 잡는다. 중심 픽셀이 line[1][1]일 때
0도 에지: abs(line[1][0] - line[1][2])가 최소
45도 에지: abs(line[0][0] - line[2][2])가 최소
90도 에지: abs(|ine[0][1] - line[2][1])가 최소
135도 에지: abs(line[0][2] - line[2][0])가 최소
Edge 방향의 3 픽셀 평균값으로 중심 픽셀 값을 대체하면 edge는 보존하면서 mean filter를 적용한 효과를 얻을 수 있다.
컬러를 양자화하는 방법으로 median-cut 알고리즘 이외에도 Octree을 이용한 알고리즘도 많이 쓰인다. (페인트샵 프로를 보면 이 두 가지 방법과 더불어 간단한 websafe 양자화 방법을 이용한다). Octree는 8개의 서브 노드를 가지는 데이터 구조이다. 이는 R, G, B의 비트 평면에서의 비트 값(각각의 레벨에서 8가지가 나옴)을 서브 노드에 할당하기 편리한 구조이다. 풀컬러를 이 Octree를 이용해서 표현을 하면 깊이가 9인 트리가 생성이 된다 (root + 각각의 비트 평면 레벨 = 8^8 = num of true colors). Octree quantization은 이 트리의 깊이를 조절하여서 leaf의 수가 원하는 컬러 수가 되도록 조절하는 알고리즘이다. 전체 이미지를 스캔하면서 트리를 동적으로 구성하고 난 후 트리의 leaf의 수가 원하는 컬러수보다 작으면 각각의 leaf가 표현하는 컬러를 팔레트로 만들면 된다. 그러나 컬러를 삽입하면서 만들어지는 leaf의 수가 원하는 컬러 개수보다 많아지는 경우는 가장 깊은 leaf 노드를 부모 노드에 병합시켜서 leaf 노드의 수를 줄이는 과정을 시행한다. 이 병합 과정은 원래 leaf 노드들의 컬러 평균을 취하여 부모 노드에 전달한다. 따라서 Octree 알고리즘은 RGB 컬러에서 상위 비트가 컬러에 대표성을 가지도록 하위 비트 값을 병합하여서 컬러 수를 줄이는 방법을 이용한 것이다. 특정 RGB 비트 평면에서 R, G, B비트 값을 이용하여서 child-노드의 인덱스를 만드는 방법은
child-node index = (R-비트<<2)|(G-비트<<1)|(B-비트) ;
(R, G, B)=(109,204,170)의 경우;
node | level | 0 1 2 3 4 5 6 7 ------------------------- R | 0 1 1 0 1 1 0 1 G | 1 1 0 0 1 1 0 0 B | 1 0 1 0 1 0 1 0 ------|------------------ child | 3 6 5 0 7 6 1 4 index | Octree 알고리즘은 컬러 이미지를 스캔하면서 트리를 동적으로 구성할 수 있으므로 median-cut 알고리즘보다도 메모리 사용에 더 효과적인 방법을 제공한다. 그리고 트리 깊이를 제한하여 일정 깊이 이상이 안되도록 만들 수 있으므로 빠른 알고리즘을 구현할 수 있다. 최종적으로 팔레트를 구성하는 컬러 값은 leaf 노드에 축적된 컬러의 평균값이 된다 (일반적으로 leaf-노드가 나타내는 비트 값과는 불일치가 생긴다). 이 알고리즘은 재귀적인 방법을 이용하면 쉽게 구현이 가능하고, 또한 웹상에서 구현된 소스도 찾을 수 있다.
참고 논문: "A Simple Method for Color Quantization: Octree Quantization." by M. Gervautz and W. Purgathofer 1988.
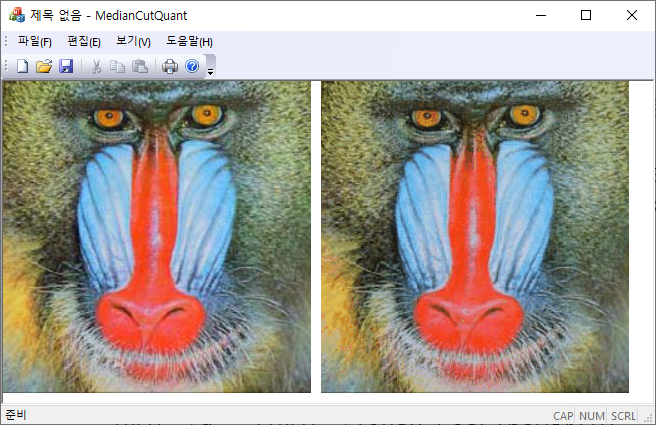
256 컬러 이미지(트리 깊이 = 5): RGB 값이 주어지면 전체 트리에서 해당 leaf을 찾아서 팔레트 인덱스를 얻는다. 이와는 다른 방법으로는 팔레트가 주어졌으므로 주어진 RGB 값과 가장 가까운 유클리디안 거리를 주는 팔레트의 인덱스를 할당하는 방법도 있다. 이 방법을 이용하면 아래의 결과와 약간 차이가 생긴다.
컬러 영상을 처리할 때 가장 흔히 사용하는 컬러 표현은 RGB 컬러이다. 이것은 R, G, B에 각각 8-비트를 할당하여 256-단계를 표현할 수 있게 하여, 전체적으로 256x256x256=16777216가지의 컬러를 표현할 수 있게 하는 것이다. 그러나 인간의 눈은 이렇게 많은 컬러를 다 구별할 수 없으므로 24-비트 RGB 컬러를 사용하는 경우는 대부분의 경우에 메모리의 낭비와 연산에 오버헤드를 가져오는 경우가 많이 생긴다. RGB 컬러 영상을 R, G, B를 각각 한축으로 하는 3차원의 컬러 공간에서의 벡터(점)로 표현이 가능하다. 컬러 영상의 픽셀들이 RGB삼차원의 공간에 골고루 펴져 있는 경우는 매우 드물고, 많은 경우에는 이 컬러 공간에서 군집(groups)을 이루면서 분포하게 된다. 하나의 군(group)은 유사한 RGB 값을 갖는 픽셀들로 구성이 되므로, 이 군에 포함이 되는 픽셀들에게 (군의 중앙에 해당하는) 대표적인 컬러 값을 대체하면 그 군에 포함이 된 픽셀은 이젠 RGB공간에서 한 점으로 표현이 되고, RGB공간상에는 픽셀 수만큼의 점이 있는 것이 아니라, 대표 RGB 값에 해당하는 점만이 존재하게 된다. 따라서 적당한 Lookup테이블(colormap)을 이용하면, 적은 메모리 공간만을 가지고도 원본의 컬러와 유사한 컬러를 구현할 수 있다.
이제 문제는 원래의 컬러 공간을 어떻게 군집화 하는가에 대한 것으로 바뀌었다. 간단한 방법으로는 원래의 컬러 영상이 차지는 하는 RGB공간에서의 영역을 감싸는 최소의 박스를 찾고, 이것을 원하는 최종적으로 원하는 컬러수만큼의 박스로 분할을 하는 것이다. 그러나 박스를 어떨게 분할을 해야만 제대로 컬러를 나누고, 또한 효율적으로 할 수 있는가를 고려해야 한다. 분할된 박스의 크기가 너무 크면 제대로 된 대푯값을 부여하기가 힘들어지고, 너무 작게 만들면 원하는 수에 맞추기가 어렵다.
Median-Cut 양자화(quantization)에서 사용하는 방법은 박스의 가장 긴축을 기준으로 그 축으로 projection 된 컬러 히스토그램의 메디안 값을 기준으로 분할을 하여서 근사적으로 픽셀들을 절반 정도 되게 분리를 한다 (한축에 대한 메디안이므로 정확히 반으로 분리되지 않는다). 두 개의 박스가 이렇게 해서 새로 생기는데, 다시 가장 많은 픽셀을 포함하는 박스를 다시 위의 과정을 통해서 분할을 하게 된다. 이렇게 원하는 수의 박스를 얻을 때까지 위의 과정을 반복적으로 시행을 하게 된다.
여기서 원래의 컬러 값을 모두 이용하게 되면 계산에 필요한 히스토그램을 만들기 위해서 너무 많은 메모리를 사용하게 되고 이것이 또한 연산의 오버헤드로 작용하게 되므로 RGB 컬러 비트에서 적당히 하위 비트를 버리면, 초기의 RGB공간에서의 histogram의 크기를 줄일 수 있게 된다.(보통 하위 3-비트를 버려서, 각각 5-비트만 이용하여, 전체 컬러의 개수를 32x32x32= 32768로 줄인다)
이렇게 RGB공간에서의 컬러 분포가 몇 개의 대표적인 컬러(예:박스의 중앙값)로 줄어들면(양자화 과정:: 공간에 연속적인 분포가 몇 개의 점으로 대체됨), 원본 영상의 각각의 픽셀에서의 대체 컬러 값은 원래의 컬러와 가장 유사한, 즉 RGB 공간에서 Euclidean 거리가 가장 작은 박스의 컬러로 대체하면 된다.
그러나 너무 적은 수의 컬러로 줄이게 되면 인접 픽셀 간의 컬러 값의 차이가 눈에 띄게 나타나는 현상이 생기게 된다. 이러한 것을 줄이기 위해서는 디더링(dithering) 과정과 같은 후처리가 필요하게 된다.
int MedCutQuantizer(CRaster& raster, CRaster& out8) {
const int MAX_CUBES = 256;
const int HSIZE =32 * 32 * 32; // # of 15-bit colors;
int hist[HSIZE] = {0};
CSize sz = raster.GetSize();
for (int y = 0; y < sz.cy; y++) {
BYTE *p = (BYTE *)raster.GetLinePtr(y);
for (int x = 0; x < sz.cx; x++) {
int b = *p++; int g = *p++; int r = *p++;
hist[bgr15(b, g, r)]++;
}
}
std::vector<int> hist_ptr;
for (int color15 = 0; color15 < HSIZE; color15++)
if (hist[color15] != 0) {
// 0이 아닌 히스토그램의 bin에 해당하는 15비트 컬러를 줌;
hist_ptr.push_back(color15);
}
std::vector<Cube> cubeList;
Cube cube(0, hist_ptr.size()-1, sz.cx * sz.cy, 0);
shrinkCube(cube, &hist_ptr[0]);
cubeList.push_back(cube);
while (cubeList.size() < MAX_CUBES) {
int level = 255, splitpos = -1;
for (int k = cubeList.size(); k-->0;) {
if (cubeList[k].lower == cubeList[k].upper) ; // single color; cannot be split
else if (cubeList[k].level < level) {
level = cubeList[k].level;
splitpos = k;
}
}
if (splitpos == -1) // no more cubes to split
break;
// Find longest dimension of this cube
Cube cube = cubeList[splitpos];
int dr = cube.rmax - cube.rmin;
int dg = cube.gmax - cube.gmin;
int db = cube.bmax - cube.bmin;
int longdim = 0;
if (dr >= dg && dr >= db) longdim = 0;
if (dg >= dr && dg >= db) longdim = 1;
if (db >= dr && db >= dg) longdim = 2;
// 가장 넓게 분포한 color를 colorTab의 15비트 컬러의 상위비트 이동;
reorderColors(&hist_ptr[0], cube.lower, cube.upper, longdim);
// hist_ptr값을 증가 순서로 바꿈->가장 폭이 넓은 컬러 방향으로 정렬됨;
quickSort(&hist_ptr[0], cube.lower, cube.upper);
// hist_ptr을 다시 원컬러로 복구;
restoreColorOrder(&hist_ptr[0], cube.lower, cube.upper, longdim);
// Find median
int count = 0;
int med = 0;
for (med = cube.lower; med < cube.upper; med++) {
if (count >= cube.count/2) break;
count += hist[hist_ptr[med]];
}
// cube에 들어있는 color의 median을 기준으로 두개 cube로 쪼김;
// 낮은 쪽은 원래 cube를 대체하고 높은 쪽은 새로 list에 추가;
Cube cubeLow(cube.lower, med - 1, count, cube.level + 1);
shrinkCube(cubeLow, &hist_ptr[0]);
cubeList[splitpos] = cubeLow; // add in old slot
//
Cube cubeHigh(med, cube.upper, cube.count - count, cube.level + 1);
shrinkCube(cubeHigh, &hist_ptr[0]);
cubeList.push_back(cubeHigh);
}
// 각 cube에 포함된 컬러를 하나의 대표값으로 설정;
// 대표값은 cube내 컬러의 평균이다;
BYTE rLUT[256], gLUT[256], bLUT[256];
for (int k = cubeList.size(); k-->0;) {
int rsum = 0, gsum = 0, bsum = 0;
Cube &cube = cubeList[k];
for (int i = cube.lower; i <= cube.upper; i++) {
int color15 = hist_ptr[i];
rsum += getRed(color15) * hist[color15];
gsum += getGreen(color15) * hist[color15];
bsum += getBlue(color15) * hist[color15];
}
rLUT[k] = int(rsum / (double)cube.count + .5);
gLUT[k] = int(gsum / (double)cube.count + .5);
bLUT[k] = int(bsum / (double)cube.count + .5);
}
// 각 cube에 포함된 color를 대표하는 컬러값을 쉽게 찾도록 lookup table
// 설정함;
BYTE inverseMap[HSIZE];
for (int k = cubeList.size(); k-->0;) {
// 각 cube 내의 컬러는 하나의 대표컬러로...;
Cube& cube = cubeList[k];
for (int i = cube.lower; i <= cube.upper; i++)
inverseMap[hist_ptr[i]] = (BYTE)k;
}
// 8-bit indexed color 이미지 생성;
out8.SetDimensions(sz, 8);
for (int y = 0; y < sz.cy; y++) {
BYTE *p = (BYTE *)raster.GetLinePtr(y);
BYTE *q = (BYTE *)out8.GetLinePtr(y);
for (int x = 0; x < sz.cx; x++) {
int b = *p++; int g = *p++; int r = *p++;
*q++ = inverseMap[bgr15(b, g, r)];
}
}
// 8비트 이미지 팔레트 설정;
for (int i = 0; i < 256; i++) {
out8.m_palette[i].rgbBlue = bLUT[i];
out8.m_palette[i].rgbGreen = gLUT[i];
out8.m_palette[i].rgbRed = rLUT[i];
}
// SaveRaster(out8, "res_medcut.bmp");
return 1;
}