$n$ 차 Bezier 곡선은 두 개의 $(n - 1)$ 차 Bezier 곡선의 선형보간으로 표현할 수 있다. Bezier 곡선은 Bernstein 다항식을 이용해서도 표현할 수도 있지만, 높은 찻수의 곡선일 때는 De Casteljau's Algorithm을 이용하는 것이 수치적으로 보다 안정적인 결과를 준다.
// De Casteljau's algorithm; recursive version; slow for larger deg;
double Bezier(int deg, double Q[], double t) {
if (deg == 0) return Q[0];
else if (deg == 1) return (1-t)*Q[0] + t*Q[1];
else if (deg == 2) return (1-t)*((1-t)*Q[0] + t*Q[1]) + t*((1-t)*Q[1] + t*Q[2]);
else return (1 - t) * Bezier(deg-1, &Q[0], t) + t * Bezier(deg-1, &Q[1], t);
}
// De Casteljau's algorithm(degree=n-1);
// non-recursive. Bezier() modifies Q's;
double Bezier(int deg, double Q[], double t) {
if (deg==0) return Q[0];
else if (deg==1) return (1-t)*Q[0] + t*Q[1];
else if (deg==2) return (1-t)*((1-t)*Q[0] + t*Q[1]) + t*((1-t)*Q[1] + t*Q[2]);
for (int k = 0; k < deg; k++)
for (int j = 0; j < (deg - k); j++)
Q[j] = (1 - t) * Q[j] + t * Q[j + 1];
return Q[0];
}
std::vector<CfPt> BezierCurve(const std::vector<CfPt> &cntls, const int segments) {
std::vector<double> xp(cntls.size()), yp(cntls.size());
std::vector<CfPt> curves(segments + 1);
for (int i = 0; i <= segments; ++i) {
double t = double(i) / segments;
// clone control points; non-rec version modifies inputs;
for (int k = cntls.size(); k-->0;) {
xp[k] = cntls[k].x; yp[k] = cntls[k].y;
}
curves[i] = CfPt(Bezier(xp.size()-1, &xp[0], t), Bezier(yp.size()-1, &yp[0], t));
}
return curves;
};
FFT는 입력 데이터의 개수$(N)$가 2의 지수승으로 주어질 때 $O(N\log N)$의 연산만으로 빠르게 DFT을 수행하는 알고리즘이다. 주어진 $N$개의 data $\{F_0, F_1, ..., F_{N-1}\}$의 DFT $\{a_0, a_1,..., a_{N-1}\}$는
$$ a_k = \sum_{n = 0}^{N-1} F_n \exp\Big( -i \frac{2\pi nk }{N} \Big)=\sum_{n = 0}^{N-1} F_n (W^n )^k , \quad W = \exp\Big( -i \frac{2\pi}{N}\Big)$$ 로 표현된다. $N$이 2의 지수승으로 주어지면 이 합은 $n$이 짝수인 항과 홀수인 항으로 아래처럼 분리할 수 있다:
\begin{align} a_k &= \sum _{n=0}^{N/2-1} F_{2n} (W^{2n})^k+W^{k} \sum_{n=0}^{N/2-1} F_{2n+1}(W^{2n})^k\\ &=\text{(N/2개 even 항에 대한 DFT)} + W^k \times \text{(N/2개 odd 항에 대한 DFT)}\\ &= e_k + W^k o_k \end{align}
이는 원래의 문제가 처음 입력 데이터의 절반만 가지고 처리하는 두 개의 동일한 문제로 줄일 수 있음을 보여준다. 전형적인 divide and conquer 기법을 적용할 수 있는 구조이므로 매우 빠르게 연산을 수행할 수 있다(Cooley-Tukey algorithm). 역변환의 경우에는 twiddle factor $W$를 $W^*$로 바꾸면 되므로(전체 normalization factor $\frac{1}{N}$가 덧붙여진다) 코드에서 쉽게 수정할 수 있다: $\tt W_{im} \rightarrow - { W}_{im}$. 아래는 FFT를 재귀적으로 구현한 코드이다. 비재귀적 구현은 kipl.tistory.com/22, https://kipl.tistory.com/622에서 찾을 수 있다.
$F_n$ 인덱스의 이진비트가 twiddlefactor를 어떻게 곱해야 하는지 알려주고, 비트를 역으로 읽으면 계수가 나타나는 순서를 알 수 있게 한다.
#define TWOPI 6.28318530717958647693
void split(int N, double* data) {
if (N == 8) {
double t1 = data[4]; data[4] = data[1];
double t2 = data[2]; data[2] = t1; data[1] = t2;
t1 = data[5]; data[5] = data[3];
t2 = data[6]; data[6] = t1; data[3] = t2;
return;
}
double *tmp = new double [N / 2];
for (int i = 0; i < N / 2; i++) //copy odd elements to tmp buffer;
tmp[i] = data[2 * i + 1];
for (int i = 0; i < N / 2; i++) // move even elements to lower half;
data[i] = data[2 * i];
for (int i = 0; i < N / 2; i++) // move odd elements to upper half;
data[i + N / 2] = tmp[i];
delete [] tmp;
}
void fft4(double *re, double *im) {
double tr1 = re[0]-re[2]+im[1]-im[3];
double ti1 = im[0]-im[2]-re[1]+re[3];
double tr2 = re[0]+re[2]-re[1]-re[3];
double ti2 = im[0]+im[2]-im[1]-im[3];
double ti3 = im[0]-im[2]+re[1]-re[3];
double tr3 = re[0]-re[2]-im[1]+im[3];
re[0] = re[0]+re[2]+re[1]+re[3];
im[0] = im[0]+im[2]+im[1]+im[3];
re[1] = tr1; im[1] = ti1;
re[2] = tr2; im[2] = ti2;
re[3] = tr3; im[3] = ti3;
}
int fft ( int N, double* re, double* im ) {
if (N <= 0 || N & (N-1)) return 0; // N is not a power of 2;
if ( N < 2 ) return 1;
else if (N == 2) {
double tr1 = re[0]-re[1], ti1 = im[0]-im[1];
re[0] = re[0]+re[1]; im[0] = im[0]+im[1];
re[1] = tr1; im[1] = ti1;
return 1;
} else if (N == 4) {
fft4(re, im);
return 1;
}
split ( N, re);
split ( N, im);
fft ( N / 2, &re[ 0], &im[ 0] );
fft ( N / 2, &re[N / 2], &im[N / 2] );
for ( int k = 0; k < N / 2; k++ ) {
double Ere = re[k];
double Eim = im[k];
double Ore = re[k + N / 2];
double Oim = im[k + N / 2];
double Wre = cos ( TWOPI * k / N ); //real part of twiddle factor:W
double Wim = -sin ( TWOPI * k / N ); //imag part of twiddlw factor:W
double WOre = Wre * Ore - Wim * Oim;
double WOim = Wre * Oim + Wim * Ore;
re[k] = Ere + WOre;
im[k] = Eim + WOim;
re[k + N / 2] = Ere - WOre;
im[k + N / 2] = Eim - WOim;
}
return 1;
};
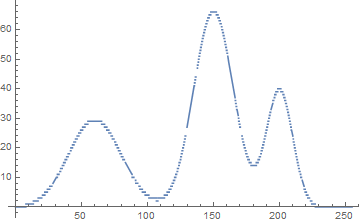
6개의 주파수 $\{f_i = 2, 5, 9, 11, 21, 29\text{Hz}\}$가 섞인 신호 $s(t)$를 $[0,1]$ 초 구간에서 일정한 간격으로 sampling 해서 64개 data를 얻고(Nyquist frequency = 32Hz), 이에 대해 FFT를 수행한다.
$$s(t)=\sum_{i=0}^{5} (i+1) \cos(2\pi f_i t) $$
int fft_test_main() {
const int samples = 64;
double re[samples], im[samples];
const int nfreqs = 6;
double freq[nfreqs] = {2, 5, 9, 11, 21, 29};
for (int i = 0; i < samples; i++) {
double signal = 0;
for (int k = 0; k < nfreqs; k++)
signal += (k + 1) * cos(TWOPI * freq[k] * i / samples);
re[i] = signal;
im[i] = 0.;
}
fft(samples, &re[0], &im[0]);
for (int i = 0; i < samples; i++) TRACE("%d, %f, %f\n", i, re[i], im[i]);
return 0;
}
Otsu 알고리즘은 이미지를 이진화시키는데 기준이 되는 값을 통계적인 방법을 이용해서 결정한다. 같은 클래스(전경/배경)에 속한 픽셀의 그레이 값은 유사한 값을 가져야 하므로 클래스 내에서 픽셀 값의 분산은 되도록이면 작게 나오도록 threshold 값이 결정되어야 한다. 또 잘 분리가 되었다는 것은 클래스 간의 거리가 되도록이면 멀리 떨어져 있다는 의미이므로 클래스 사이의 분산 값은 커야 함을 의미한다. 이 두 가지 요구조건은 동일한 결과를 줌을 수학적으로 보일 수 있다.
이미지의 이진화는 전경과 배경을 분리하는 작업이므로 클래스의 개수가 2개, 즉, threshold 값이 1개만 필요하다. 그러나 일반적으로 주어진 이미지의 픽셀 값을 임의의 개수의 클래스로 분리할 수도 있다. 아래의 코드는 주어진 이미지의 histogram을 Otsu의 아이디어를 이용해서 nclass개의 클래스로 분리하는 알고리즘을 재귀적으로 구현한 것이다. 영상에서 얻은 히스토그램을 사용하여 도수를 계산할 수 있는 0차 cumulative histogram($\tt ch$)과 평균을 계산할 수 있는 1차 culmuative histogram($\tt cxh$)을 입력으로 사용한다.
Input = a set S of n points
Assume that there are at least 2 points in the input set S of points
QuickHull (S) {
// Find convex hull from the set S of n points
Convex Hull := {}
가장 왼쪽(A)과 오른쪽(B)에 있는 두 점을 찾아 convec hull에 추가;
선분 AB을 기준으로 나머지 (n-2)개 점들을 두 그룹 S1과 S2로 나눔;
S1 = 선분 AB의 오른쪽에 놓인 점;
S2 = 선분 BA의 오른쪽에 놓인 점;
FindHull (S1, A, B)
FindHull (S2, B, A)
};
FindHull (Sk, P, Q) {
If Sk has no point,
then return.
선분 PQ에서 가장 멀리 떨어진 점(C)을 찾아 convex hull에서 P와 Q의 사이에 추가;
세점 P, C, Q는 나머지 Sk의 나머지 점들을 세 그룹S0, S1, and S2
S0 = 삼각형 PCQ에 포함되는 점;
S1 = 선분 PC의 오른쪽에 놓인 점;
S2 = 선분 CQ의 오른쪽에 놓인 점;
FindHull(S1, P, C)
FindHull(S2, C, Q)
}
Output = convex hull
void findMaxMin(std::vector<CPoint>& pts) {
int minx = pts[0].x, maxx = minx;
int minid = 0, maxid = 0;
for (int i = pts.size(); i-->1;) {
if (pts[i].x > maxx) maxid = i, maxx = pts[i].x;
if (pts[i].x < minx) minid = i, minx = pts[i].x;
}
SWAP_POINT(pts[0], pts[minid]); if (maxid == 0) maxid = minid;
SWAP_POINT(pts[1], pts[maxid]);
};
void hullToPolyline(std::vector<CPoint>& hull);
std::vector<CPoint> quickHull(const std::vector<CPoint>& pts) {
if (pts.size() < 3) std::vector<CPoint> ();//null_vector;
//Find left and right most points, say A & B, and add A & B to convex hull ;
findMaxMin(pts);
std::vector<CPoint> hull;
hull.push_back(pts[0]);
hull.push_back(pts[1]);
int j = 2;
for (int i = 2; i < pts.size(); i++) {
if (leftSide(pts[i], pts[0], pts[1])) {
SWAP_POINT(pts[i], pts[j]);
j++;
}
}
//2,3,...,j-1;
findHull(&pts[2], j-2, pts[0], pts[1], hull);
//j,j+1,...,pts.size()-1;
if (j < pts.size()) // in order to avoid dereferencing &pts[pts.size()];
findHull(&pts[j], pts.size()-j, pts[1], pts[0], hull);
hullToPolyline(hull);
return hull;
};
출력 hull은 단순히 convex hull을 구성하는 정렬이 안된 점들만 주므로, hull의 에지를 구하고 싶으면 추가적인 수정이 필요함.
static int cmph(const void *a, const void *b) {
CPoint *A = (CPoint *)a , *B = (CPoint *)b ;
int v = (A->x - B->x) ;
if (v > 0 ) return 1;
if (v < 0 ) return -1;
v = B->y - A->y ;
if (v > 0 ) return 1;
if (v < 0 ) return -1;
return 0;
};
static int cmpl(const void * a, const void *b) {
return cmph(b, a);
};
void hullToPolyline(std::vector<CPoint>& hull) {
CPoint A = hull[0];
CPoint B = hull[1];
// 가장 멀리 떨어진 두 점(hull[0], hull[1])을 연결하는 직선을 기준으로 프로젝션을 구하여서 순차적으로
int k = 2;
for (int i = 2; i < hull.size(); i++) {
if (leftSide(hull[i], A, B)) {
SWAP_POINT(hull[i], hull[k]); k++;
};
};
// k-1; last index of hull left side of line(A,B);
// upper part reordering:
qsort(&hull[0], k, sizeof(CPoint), cmph);
//lower part reordering;
if (k < hull.size())
qsort(&hull[k], hull.size()-k, sizeof(CPoint), cmpl);
}
};
또한 입력점들의 순서를 그대로 유지하고 싶으면, double pointer를 이용하거나 복사복은 이용하여야 한다.
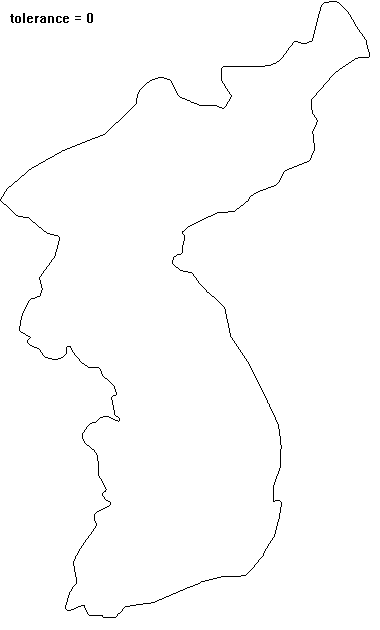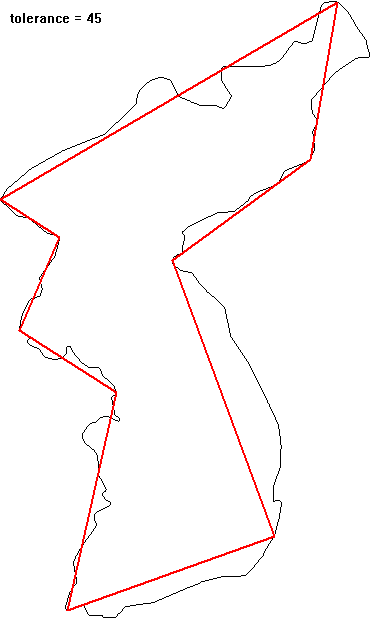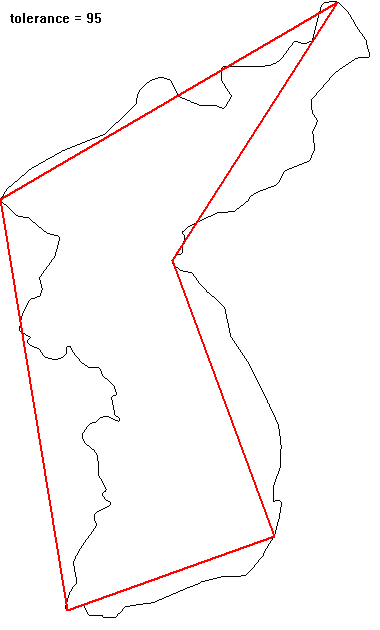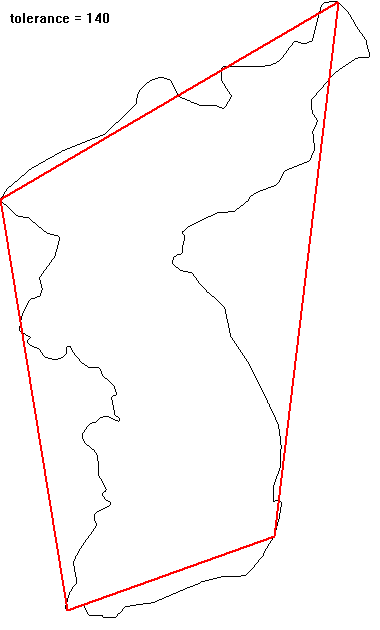
영상에서 추출한 객체(object)의 경계선은 객체의 모양에 대한 많은 정보를 담고 있지만, 어떤 경우에는 불필요하게 많은 정보가 될 수도 있다. 이 경우 원래의 경계를 충분히 닮은 다각형으로 간략화하여서 불필요한 정보를 제거할 수 있다. 이 다각형으로의 근사가 물체의 경계를 얼마나 제대로 표현할 수 있는지에 대한 기준이 있어야 한다. $N$개의 점 $\{(x_i, y_i) | i = 1,... ,N\}$으로 표현된 경계가 있다고 하자. 가장 단순한 근사는 가장 멀리 떨어진 두 점($A, B$)으로 만들어진 선분일 것이다(선분의 길이가 대략적인 물체의 크기를 주고, 선분 방향이 물체의 orientation을 알려준다). 이 선분을 기준으로 다시 가장 멀리 떨어진 점($C$)을 찾아서 일정 거리 이상 떨어져 있으면 꼭짓점으로 추가하여 두 개의 선분으로 분할한다. 두 개의 선분에 대해서 동일한 분할 작업을 재귀적으로 반복하므로 좀 더 정밀하게 물체를 표현하는 다각형을 찾을 수 있다. 선분에서 가장 멀리 떨어진 지점이 기준 거리 이내이면 분할을 멈춘다. 닫힌 다각형 근사일 때는 시작점 = 끝점으로 조건을 부여하면 된다.
** open polyline으로 우리나라 경계를 단순화시키는 예: top-right 쪽이 시작과 끝이므로 simplication 과정에서 변화지 않는다.
// distance square from P to the line segment AB ;
double pt2SegDist2(CPoint P, CPoint A, CPoint B) ;
// P에서 두 점 A, B을 연결하는 선분까지 거리
double pt2SegDist2(CPoint P, CPoint A, CPoint B) {
double dx = B.x - A.x, dy = B.y - A.y ;
double lenAB2 = dx * dx + dy * dy ;
double du = P.x - A.x, dv = P.y - A.y ;
if (lenAB2 == 0.) return du * du + dv * dv;
double dot = dx * du + dy * dv ;
if (dot <= 0.) return du * du + dv * dv;
else if (dot >= lenAB2) {
du = P.x - B.x; dv = P.y - B.y;
return du * du + dv * dv;
} else {
double slash = du * dy - dv * dx ;
return slash * slash / lenAB2;
}
};
// recursive Douglas-Peucker 알고리즘;
void DouglasPeucker(double tol, std::vector<CPoint>& vtx, int start, int end,
std::vector<bool>& mark) {
if (end <= start + 1) return; //종료 조건;
// vtx[start] to vtx[end]을 잇는 선분을 기준으로 분할점을 찾음;
int break_id = start; // 선분에서 가장 먼 꼭짓점;
double maxdist2 = 0;
const double tolsq = tol * tol;
for (int i = start + 1; i < end; i++) {
double dist2 = pt2SegDist2(vtx[i], vtx[start], vtx[end]);
if (dist2 <= maxdist2) continue;
break_id = i;
maxdist2 = dist2;
}
if (maxdist2 > tolsq) { // 가장 먼 꼭짓점까지 거리가 임계값을 넘으면 => 분할;
mark[break] = true; // vtx[break_id]를 유지;
// vtx[break_id] 기준으로 좌/우 polyline을 분할시도;
DouglasPeucker(tol, vtx, start, break_id, mark);
DouglasPeucker(tol, vtx, break_id, end, mark);
}
};
// driver routine;
std::vector<CPoint> polySimplify(const double tol, const std::vector<CPoint> &V) {
if (V.size() <= 2) return V;
std::vector<bool> mark(V.size(), false); // 꼭짓점 마킹용 버퍼;
// 알고리즘 호출 전에 너무 붙어있는 꼭짓점을 제거하면 보다 빠르게 동작;
// 폐곡선이 아닌 경우 처음,끝은 marking;
// 폐곡선은 가장 멀리 떨어진 두점중 하나만 해도 충분;
mark.front() = mark.back() = true;
DouglasPeucker( tol, V, 0, V.size()-1, mark );
// save marked vertices;
std::vector<CPoint> decimated;
for (int i = 0; i < V.size(); i++)
if (mark[i]) decimated.push_back(V[i]);
return decimated;
}
nonrecursive version:
// nonrecursive version;
std::vector<CPoint> DouglasPeucker_nonrec(const double tol, const std::vector<CPoint>& points) {
if (points.size() <= 2) return std::vector<CPoint> (); //null_vector;
double tol2 = tol * tol; //squaring tolerance;
// 미리 가까이 충분히 가까이 있는 꼭지점은 제거하면 더 빨라짐;
std::vector<CPoint> vt;
vt.push_back(points.front()) ; // start at the beginning;
for (int i = 1, pv = 0; i < points.size(); i++) {
int dx = points[i].x - points[pv].x, dy = points[i].y - points[pv].y;
double dist2 = dx * dx + dy * dy ;
if (dist2 < tol2) continue;
vt.push_back(points[i]);
pv = i; // 다시 거리를 재는 기준점;
}
if (vt.back()!=points.back()) vt.push_back(points.back()); // finish at the end
points.swap(vt);
//
std::vector<bool> mark(points.size(), false); // vertices marking
std::vector<int> stack(points.size()); // 분할된 라인 처음-끝 저장;
// 폐곡선이 아닌 경우 처음,끝은 marking;
// 폐곡선은 가장 멀리 떨어진 두점 중 하나만 해도 충분
mark.front() = mark.back() = true;
int top = -1;
// 분할 해야할 폴리라인의 양끝점을 스택에 넣음;
stack[++top] = 0;
stack[++top] = points.size() - 1;
while (top >= 0) {
// 분할을 시도할 구간의 두 끝점을 꺼냄;
int end = stack[top--];
int start = stack[top--];
// 최대로 멀리 떨어진 점;
double max_distance2 = 0;
int break_id = -1;
for (int i = start + 1; i < end; i++) {
double dsq = pt2SegDist2(points[i], points[start], points[end]);
if (dsq > max_distance2) {
max_distance2 = dsq;
break_id = i;
}
}
// 주어진 임계값 이상 떨어졌으면 꼭지점을 유지하도록 표시;
if (max_distance2 > tol2) {
mark[break_id] = true;
// 주어진 꼭지점을 기준으로 양쪽을 다시 검사하기 위해 스택에 쌓음;
stack[++top] = start;
stack[++top] = break_id;
stack[++top] = break_id;
stack[++top] = end;
}
}
// marking 된 꼭지점을 출력;
std::vector<CPoint> decimated;
for (int i = 0; i < points.size(); i++)
if (mark[i]) decimated.push_back(points[i]);
return decimated;
}